
“Using Integrated City Data to Identify and Intervene Early on Housing-related Public Health Problems”
Journal of Public Health Management and Practice
Action Insights







Last Updated
Topic
Data and Evidence
Locations
North America, Northeast Region, United States
Housing inspections are traditionally done periodically, in response to complaints, or when owners or renters turn over. This study supported by the Bloomberg Harvard City Leadership Initiative shows that machine learning can help inspectors identify risky homes nearly twice as fast as conventional practices.
Read the Action Insights below, or download as a PDF for use later.
Is it possible to save lives, time, and money, all at once? Could you use data that you already have to do it? As we describe in our peer-reviewed paper, the answer is yes. We found that machine learning could help a city identify properties with health-threatening housing code violations nearly twice as fast as conventional practices.
More and more cities—large and small—are harnessing machine learning and existing municipal data to help power charge a city’s efforts to deliver services to those who need them most. In Chelsea, Massachusetts, a city of more than 40,000 people packed into less than two square miles just north of Boston, our research team worked with the city to do just that.
Chelsea residents are predominantly recent immigrants, people of color, and low-income families. With skyrocketing rental costs and stagnant wages, overcrowded conditions in substandard housing are common. The city’s housing inspectors encounter families doubling or tripling up together, living in unfinished basements, windowless closets, and open-air porches. Some lack access to bathrooms, kitchens, and even plumbing. Setups like these harken back to an earlier era, an era when we learned that unacceptable living conditions not only devastate families but offer fertile ground for disease to flourish and fires to blaze, putting us all at risk.
In 2019, our research team (that holds expertise in public health, public policy, and data science) partnered with Chelsea’s Inspectional Services Department (ISD) to see if we could use city data to root out long-hidden, health-threatening housing code violations and nip others cropping up in the bud. More specifically, could ISD use a data-driven model to be better and faster at finding health-threatening housing code violations?
Housing codes represent the absolute minimum standards for safe housing—such as protection from the elements, a way to escape from fire, and working smoke detectors—and violations can be hard to find.
Many violations are never called in for fear of landlords raising rent, language barriers, or residents simply not knowing that they can. Often, the most vulnerable residents are the least likely to complain. On the other hand, cities can only inspect so many properties in a day. Finding—and prioritizing—the people that live in the riskiest places could help inspectors enforce housing codes not only more quickly and effectively, but more equitably, too.
To gather clues on where to find code violations, our team used data from inspections that the city had done proactively from 2015 to 2018, and the expertise of the city’s housing inspectors. We then trained a computer (using a process called machine learning) to make educated guesses about which properties should be inspected first (predictive analytics). We found that “listening” to these predictions could nearly double the number of productive inspections. That is, the “hit rate” for inspections identifying health-threatening housing code violations could increase by a factor of 1.8. Chelsea could now identify and resolve more housing code violations without increasing inspection resources. In essence, the city could “do more with less.”
And, as always, there is still more to do. Now that the city has become better at finding risky conditions, our team is helping look at how to resolve those risky conditions. Currently, Chelsea is partnering with a local social service agency so inspectors can do more than issue citations. They can now make referrals for those who face challenges complying with housing codes because they experience mental illness or poverty, connecting people to the services they need to live healthier lives.
While our study demonstrated that machine learning could help a city save lives, time, and money by more accurately identifying unsafe and unhealthy housing earlier than conventional code enforcement, we believe that many more machine learning applications are waiting to be discovered. To help fulfill that potential, we offer three lessons from the Chelsea study:
No matter the size or state of the city, machine learning and predictive analytics can help cut wasted energy by identifying high priorities faster, catching problems earlier, and finding the most vulnerable residents before it’s too late. And in the world of city services, being more effective, efficient, and equitable not only saves time and taxpayer dollars, but it can save lives.
Journal of Public Health Management and Practice
Data-Smart City Solutions
Data-Smart City Solutions
Harvard Ash Center
Harvard Ash Center
Data-Smart City Solutions
The Harvard Gazette
Perspectives on Public Management and Governance
International Journal of Environmental Research and Public Health
More Resources Like This

Action Insights
Data and Evidence, Innovation
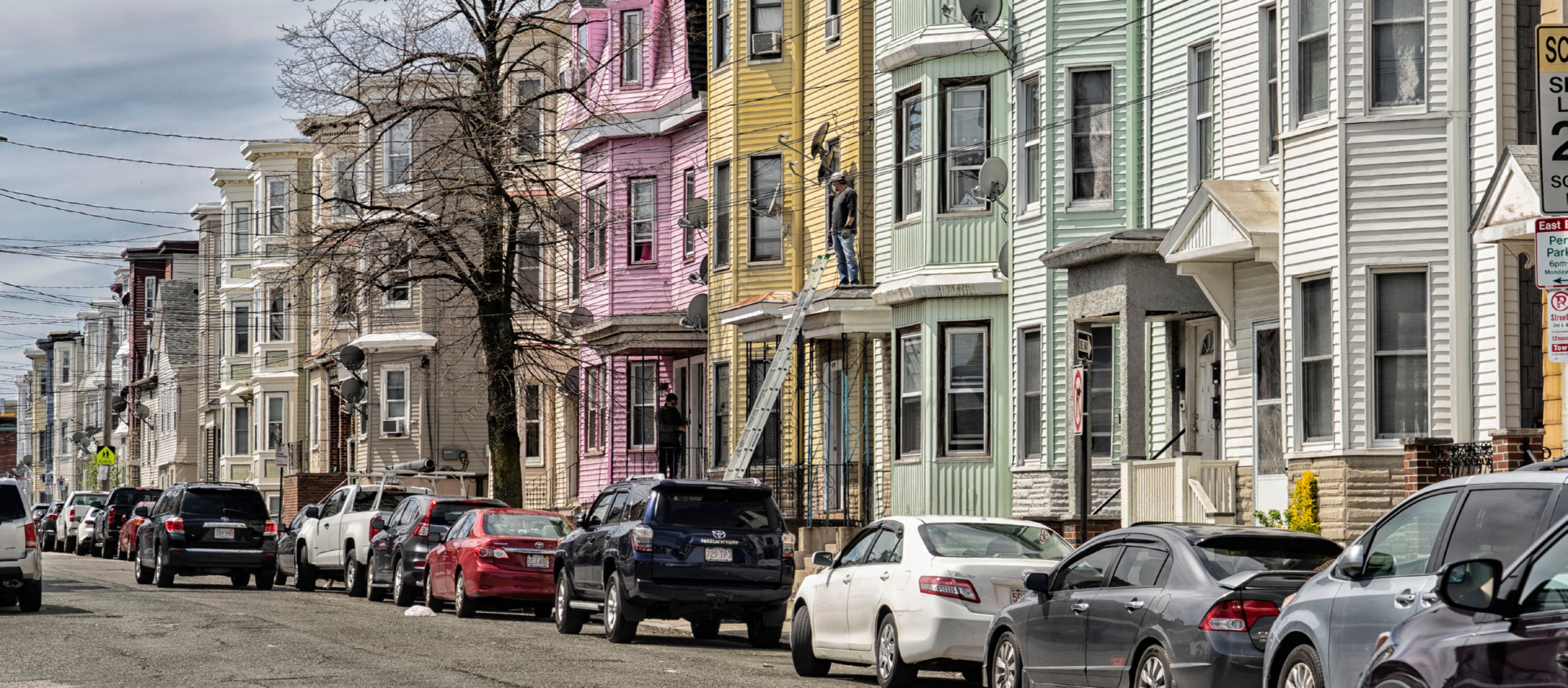
Action Insights
Data and Evidence, Strategic Leadership and Management

